
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 | 31 |
- springboot
- DIP
- assertThrows
- java
- SQL
- 생성자 주입
- DI
- db
- resultMap
- Effective Java
- 스프링부트
- 스프링
- sqld
- 스프링 프레임워크
- assertThat
- 필드 주입
- 스프링 부트
- mybatis
- JPA
- 스프링 빈
- thymeleaf
- @Configuration
- 스프링 부트 기본
- spring
- 싱글톤
- jdbc
- 스프링 컨테이너
- kafka
- Javascript
- 스프링 부트 입문
- Today
- Total
선 조치 후 분석
Zookeeper 기본 개념 정리 본문

주키퍼(Zookeeper)
- 분산 코디네이션 서비스를 제공하는 오픈소스 프로젝트
- 직접 애플리케이션 작업을 조율하는 것을 쉽게 개발할 수 있도록 도와주는 도구
- API를 이용해 동기화나 마스터 선출 등의 작업을 쉽게 구현할 수 있게 해 준다
분산 코디네이션 서비스?
분산 시스템에서 시스템 간의 정보 공유, 상태 체크, 서버들 간의 상태를 조율하고 동기화를 위한 락 등을 처리해 주는 서비스 즉, 분산 시스템의 일관성 유지와 조정에 초점
대표적인 예
Apache Zookeeper, etcd
분산 메시징 서비스
분산 환경에서 노드 간 데이터를 비동기적으로 전달하기 위한 메시징 시스템
주된 목적은 메시지 전달과 데이터의 흐름 관리
주키퍼 기능
- 리더 선출 : 여러 노드 중 하나를 리더로 선택하여 작업을 조율
- 분산 락(Distributed Lock) : 동시에 여러 노드가 같은 리소스를 접근하지 못하도록 제어
- 메타데이터 관리 : 노드 간 상태 정보 및 설정 공유
- 노드 상태 감시 : 분산 시스템 내 노드의 가용성을 모니터링
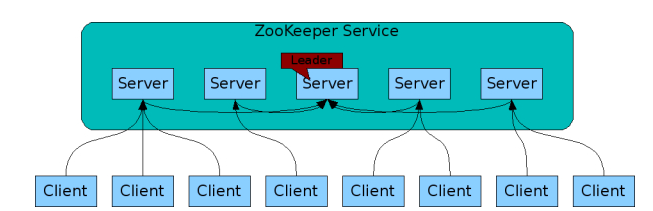
그림에서 Server가 주키퍼, 클라이언트가 카프카
기본적으로 복수 개의 주키퍼 서버의 집합인 앙상블(Ensemble)로 구성
Ensemble은 Leader-Follower 구조를 사용, Leader가 Follower에게 동기화를 위한 명령
분산 애플리케이션들이 각각 클라이언트가 되어 주키퍼 서버들과 커넥션을 맺은 후 상태 정보들을 주고받는다.
각 애플리케이션의 정보를 중앙 집중화하고 구성관리, 그룹 관리 네이밍, 동기화 등의 서비스를 제공
주키퍼의 데이터는 메모리에 저장되고, 영구 저장소에 스냅샷을 저장
주키퍼 구성
- Request Processor : Write 요청
- Zab (Zookeeper Atomic BroadCast Protocol) : Request Processor에서 처리한 요청을 트랜잭션을 생성하여
모든 서버에 전파 [ Leader-Propose > Follower-Accept > Leader-Commit] - In-Memory DB : Znode의 정보가 저장되며, 로컬 파일시스템에 Replication을 구성
주키퍼 데이터 모델 (Znode)
- 상태 정보들은 주키퍼의 지노드(ZNODE)라고 불리는 곳에 Key-Value 형태로 저장
- 지노드에 저장된 것을 이용하여 분산 어플리케이션들은 서로 데이터를 주고받음
- 파일시스템과 유사한 Shared Hierac
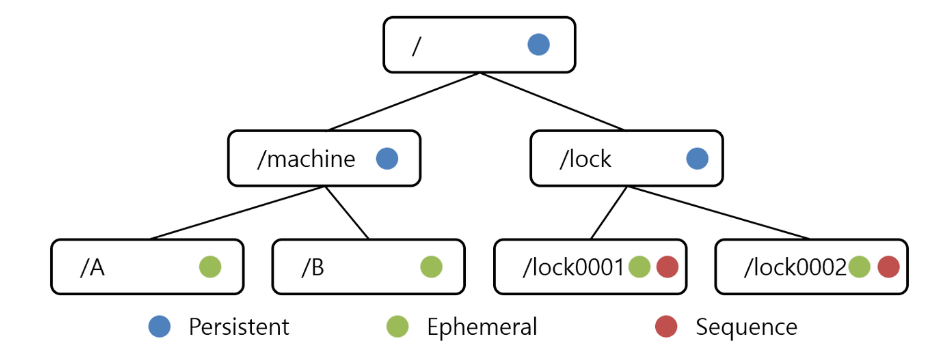
Persistent Node
- 노드에 데이터를 저장하면 일부러 삭제하지 않는 이상 삭제되지 않고 영구적으로 저장
Ephemeral Node
- 노드에 생성한 클라이언트의 세션이 연결되어 있을 경우만 유효
- 즉, 클라이언트 연결이 끊어지는 순간 삭제
- 이를 통해서 클라이언트가 연결 유/무를 판단하는 데 사용할 수 있음
Sequence Node
- 노드를 생성할 때 자동으로 Sequence 번호가 붙는 노드
- 주로 분산락을 구현하는데 이용
주키퍼의 서버를 여러대를 사용하는 이유?
주키퍼는 분산 시스템의 일부분이기 때문에 동작을 멈춘다면 분산 시스템이 멈출 수 도 있다
그래서 안정성을 확보하기 위해 클러스터로 구축한다. 클러스터는 홀수로 구축한다.
어떤 서버에 문제가 생겼을 경우 과반수 이상의 데이터를 기준으로 일관성을 맞추기 때문이다.
살아있는 노드가 과반수 이상이라면 지속적인 서비스를 제공한다.
Kafka를 사용하는 데 있어서 Zookeeper는 필수이다?
과거 Kafka2.x는 Zookeeper를 필수로 사용
하지만, Kafka2.8.0부터는 KRaft(Kafka Raft) 모드가 도입되었고, Kafka3.0 이상에서는
Zookeeper 없이도 Kafka를 실행이 가능할 수 있게 되었다.
'ETC > IT Knowledge' 카테고리의 다른 글
| REST와 MQ의 개념 및 차이점 정리 (1) | 2024.12.26 |
|---|---|
| 클러스터(Cluster)에 대하여.. (0) | 2024.12.24 |
| eGovFrame Web Project vs eGovFrame Boot Web Project 차이점 (0) | 2024.12.17 |
| MSA(Microservices Architecture)? MA(Monolithic Architecture)? 개념 및 차이 (0) | 2024.12.09 |
| MQ(Message Queue) 개념 그리고 Kafka, RabbitMQ 차 (1) | 2024.12.06 |
